Deep Learning for Coders - notas capítulo 2
Data Augmentation
Uno de los puntos interesantes del capítulo es la introducción del conjunto de técnicas bajo el nombre de data augmentation ✨. Es una idea simple pero ingeniosa ya que no va en la línea directa (y más obvia) de mejorar el desempeño del modelo a través del diseño de la arquitectura, sino el foco se mueve a los datos. Parte esencial pero definitivamente no la más popular (?). El punto es que cualquier sistema bajo la categoria de machine learning (incluyendo deep learning) tiene una relación indisoluble con los datos, y ocupar data augmentation es una forma de incrementar la diversidad de nuestro dataset usando data sintetica creada a partir del dataset original.

Enfocandonos en datos que son imagenes, la generación de nuevos datos se realiza al aplicar transformaciones sobre una imagen. Arriba se observan distintas variaciones de la misma imagen, vemos como la imagen de un elfo sufré alteraciones como rotaciones, saturación del color, etcétera. Esto ayuda aumentar artificialmente la variación en nuestros datos, y si todo sale bien lograr una mejora en la generalización del modelo. Intuitivamente esto se podría explicar porque la saturación de color ayuda a evitar que el modelo dependa mucho del color verde en detectar elfos y permitir identificarlos en otros entornos menos comunes pero probables (e.g. montañosos con paleta más cargada a colores tierra), o incorporar mayor diversidad en las poses de los dibujos de elfos que el algoritmo ve durante el entrenamiento, logrando así disminuir el sesgo de las poses más comunes con que se dibujan y representan a los elfos.
La librería fastai operativamente implementa las transformaciones de imagen
durante cada época, donde con alguna probabilidad se aplica una o más
perturbaciones sobre la imagen, o se muestra su versión de la original.
db = DataBlock(
blocks = (ImageBlock, CategoryBlock),
get_items = get_image_filees,
splitter = RandomSplitter(valid_pct=0.2, seed=42),
get_y = parent_label,
item_tfms=Resize(128),
batch_tfms=aug_transforms(mult=2)
)
dls = db.dataloaders(images_path)Recordemos que el objeto DataLoaders es una instancia de la clase encargada de
proveer mini-batches al algoritmo durante el entrenamiento y enviarlas a la GPU.
Por lo tanto, las transformaciones especificadas en el argumento batch_tfms
en DataBlock son las que se ejecutaran en la GPU para todo las imagenes
del mini-batch, transformaciones que van aplicandose época-tras-época.
Si bien el segundo capítulo no detalle mucho más, en la documentación de fastai se puede encontrar
más información de cómo aplicar varias transformaciones y combinarlas. Además,
hay metodologias para encontrar el conjunto de transformaciones más óptimo para un
dataset especifico como la detallada en el paper
AutoAugment: Learning Augmentation Policies from Data (Cubuk 2018).
De hecho, el modulo vision de PyTorch, en torchvision.transforms.AutoAugment
se encuentran los conjuntos de transformaciones óptimos según la metodologia del
paper anterior para los datasets: Imagenet, CIFAR10, y SVHN. Una
alternativa es ocupar alguna de estas transformaciones versus ocupar
transformaciones arbitrariamente definidas.
Finalmente terminar con cómo interpretar teorícamente la técnica de data augmentation. Existe una justificación bayesiana cuya línea argumentativa es tratada en el post A Bayesian view of data augmentation (O’Rourke 2019) , y también hay una breve sección en la nueva edición del libro de Kevin Murphy página 622, citó del libro: “the data augmentation mechanism can be viewed as a way to algorithmically inject prior knowledge” 💉🧠.
Cuestionario
Where do text models currently have a major deficiency?
- R: Si bien los modelos de texto son buenos generando prosa apropiada al contexto, estos modelos no son consistentes ni capaces de garantizar respuestas correctas.
What are possible negative societal implications of text generation models?
- R: Los modelos de generación de texto reproducen los sesgos implicitos contenidos bajo los textos en que fueron entrenados. Un impacto social negativo es reproducir y amplificar este tipo de sesgos debido a la facilidad con que pueden escalar ya sea en redes sociales u otras aplicaciones.
In situations where a model might make mistakes, and those mistakes could be harmful, what is a good alternative to automating a process?
- R: Utilizar un sistema en conjunto con un experto, el primero entrega recomendaciones, o alternativas como predicciones, y el experto puede utilizarlas para complementar su análisis o para validar los resultados evitando cometer errores y a la vez tomando ventaja de un sistema de apoyo. Siempre se puede descartar la sugerencia del modelo si no es pertinente.
What kind of tabular data is deep learning particularly good at?
- R: Data tabular que contiene columnas con texto (e.g. comentarios de clientes o reviews sobe una película) u otra información tabularizada pero no estructurada (e.g. imagen de avatar de los usuarios en un foro).
What’s a key downside of directly using a deep learning model for recommendation systems?
- R: Los sistemas de recomendación son buenos entregando recomendaciones que le pueden gustar al usuario pero no necesariamente son opciones de utilidad. Si un sistema de recomendación me entrega vinilos de artistas que ya conozco, no hay mucho valor en estas opciones, porque es muy probable que ya conozca todas las alternativas y no necesite un sistema de recomendación para eso.
What are the steps of the Drivetrain Approach?
- Objetivo: ¿Qué buscamos lograr con nuestro producto de datos?
- Levers: ¿Qué input podemos controlar para lograr nuestro objetivo?
- Data: ¿Qué datos disponemos o podemos adquirir que sean relevantes para llevar acabo las acciones y cumplir el ojetivo?
- Modelo: ¿Qué acciones concretas generamos en base a nuestros levers (aka inputs)?

How do the steps of the Drivetrain Approach map to a recommendation system?
- Objetivo: Aumentar las ventas a través de recomendaciones novedosas y encantadoras para nuestros clientes.
- Levers: Rankear las recomendaciones de la mejor forma posible para lograr el aumento de ventas.
- Data: ¿Qué datos necesitamos recolectar para aumentar las ventas? (e.g. reproducciones de nuevos artistas o información de las compras de última temporada).
- Modelo: Construir dos modelos de probabilidad de compra, uno condicionado en ver las recomendaciones y otro no. La diferencia entre ambas probabilidades es la función de utilidad de entregar una recomendación al cliente.
Create an image recognition model using data you curate, and deploy it on the web.
- R: Bestiario es una simple aplicación para identificar clases de criaturas (i.e. elfos, trasgos, zombies y caballeros) desde imagenes. En otro post escribire sobre los pasos y desarrollos del proyecto
What is
DataLoaders?- R: Un
DataLoaderes una clase auxiliar para implementar la abstracción de gestionar y proveer datos al modelo. Las 4 líneas de código siguientes son la funcionalidades básicas de esta clase destacadas en el capítulo:
class DataLoaders(GetAttr): def __init__(self, *loaders): self.loaders = loaders def __getitem__(self, i): return self.loaders[i] train, valid = add_props(lambda i, self: self[i])- R: Un
What four things do we need to tell fastai to create
DataLoaders?- ¿Con qué tipo de datos vamos a trabajar (e.g. imagenes, audio)? ->
blocks=(ImageBlock, CategoryBlock) - ¿Cómo obtener la lista con las observaciones (datos)? ->
get_items=get_image_files - ¿Cómo se encuentran etiquetados las observaciones? ->
get_y=parent_label - ¿Cómo crear el conjunto de validación? ->
splitter=RandomSplitter(valid_pct=0.2, seed=42)
- ¿Con qué tipo de datos vamos a trabajar (e.g. imagenes, audio)? ->
What does the
splitterparameter toDataBlockdo?- R: El argumento
splitterdentro deDataBlockespecifica el porcentaje de observaciones que serán destinadas al conjunto de validación además de garantizar la reproducibilidad de los resultados.
- R: El argumento
How do we ensure a random split always gives the same validation set?
- R: Utilizando un número de semilla (e.g.
seed=42) para garantizar que el generador de números aleatorios produzca la misma secuencia de valores y por ende resultados.
- R: Utilizando un número de semilla (e.g.
What letters are often used to signify the independent and dependent variables?
- R: La letra \(y\) se utiliza para representar la variable dependiente (i.e. output) y la \(x\) para las variables independientes (i.e. input).
What’s the difference between the crop, pad, and squish resize approaches? When might you choose one over the others?
R: Primero, es importante estandarizar nuestras imagenes para transformarlas en tensores y que luego puedan ser insumidas por la arquitectura del modelo. La mayoría de las veces que recolectamos imagenes en la web, o de diferentes fuentes, notaremos que las imagenes tendrán distintas dimensiones. ¿Cómo estandarizarlas? Hay distintas formas y cada una puede tener un impacto en la calidad de nuestros datos.
- Crop: Corta la imagen para generar un cuadrado de la dimensión
requerida usando el largo o ancho completo. Se puede perder información
relevante de la imagen respecto a la dimensión que sea truncada, como
la parte trasera un auto que puede permitir discriminar entre un tipo
de auto 🚓 y otro 🏎️. ->
Resize(128) - Pad: Agregar regiones negras en los bordes para completar las dimensiones,
lo que termina generando información nula que será simplemente pérdida
en recursos computacionales (pensemos en millones de observaciones que
necesitan esta transformación para quedar estandarizadas). ->
Resize(128, ResizeMethod.Pad, pad_mode='zeros')) - Squish: Contraemos o expandemos la imagen para lograr la dimensión
requerida. El problema es que podemos deformar el significado de lo que
representa la imagen, por ejemplo, tenemos una imagen de una tetera de té
🫖 y la debemos expandir para alcanzar las dimensiones requeridas, y la
tetera termina siendo una especie de balon más inflado ⚽ que aimensiones
reales del objeto. ->
Resize(128, ResizeMethod.Squish))
- Crop: Corta la imagen para generar un cuadrado de la dimensión
requerida usando el largo o ancho completo. Se puede perder información
relevante de la imagen respecto a la dimensión que sea truncada, como
la parte trasera un auto que puede permitir discriminar entre un tipo
de auto 🚓 y otro 🏎️. ->
¿Cuando escoger una sobre otra? Depende mucho de la naturaleza de las imagenes y que representan. Imagenes de números y letras pueden ser afectadas si se recorta alguna parte distintiva de un número particular, un 7 podría ser muy un 1 si la imagen se cropea de cierta forma. Sin embargo, si estamos identificando paisajes que son muy distintos (e.g. pradera y oceanos) el cropping no importar mucho.
What is data augmentation? Why is it needed?
- R: Data augmentation es un conjunto de técnicas para aumentar de forma artificial los datos a través de perturbaciones aleatorias sobre estos sin alterar su significado intrínsico. Por ejemplo, si rotamos o modificamos la saturación de color de una foto de un perro, esta imagen continuará siendo la representación de un perro independiente las transformaciones aplicadas. Es importante notar que en la practica, cuando se aplican estas perturbaciones, no se aumentan los datos previo al proceso de entrenamiento. Pensemos que solo entre dos transformaciones como rotación y saturación de color, el espacio de configuraciones entre el producto cruz de estas dos operaciones dan lugar a infinitas versiones de una imagen, sino mas bien durante el entrenamiento, se muestran distintas versiones de un input agregando mayor variación y diversidad durante el ajuste de parámetros.
Provide an example of where the bear classification model might work poorly in production, due to structural or style differences in the training data.
- R: Los ángulos de las fotos utilizadas para el conjunto de entrenamiento pueden variar a las obtenidas respecto a la posición de la camara en parque o lugar en que se utilicé el modelo. Otro problema pueden ser las variaciones del entorno en producción que no fueron capturadas en el dataset de entrenamiento apropiadamente como cambios de luminosidad por estaciones del año.
What is the difference between
item_tfmsandbatch_tfms?- R: La diferencia entre
item_tfmsybatch_tfmses que el primero se aplica previo al proceso de entrenamiento a modo de pre-proceso de imagenes (e.g. estandarizar todas las imagenes a ciertas dimensiones como 128x128) y utiliza la CPU. En cambio,batch_tfmsse aplica cada vez que elDataLoaderentrega un mini-batch, o conjunto de observaciones, al modelo y generalmente se aplican usando la GPU para aplicar de manera eficiente las transformaciones sobre el mini-batch completo y que el modelo realice el ajuste de parámetros con las perturbaciones aleatorias particulares en esa epoch.
- R: La diferencia entre
What is a confusion matrix?
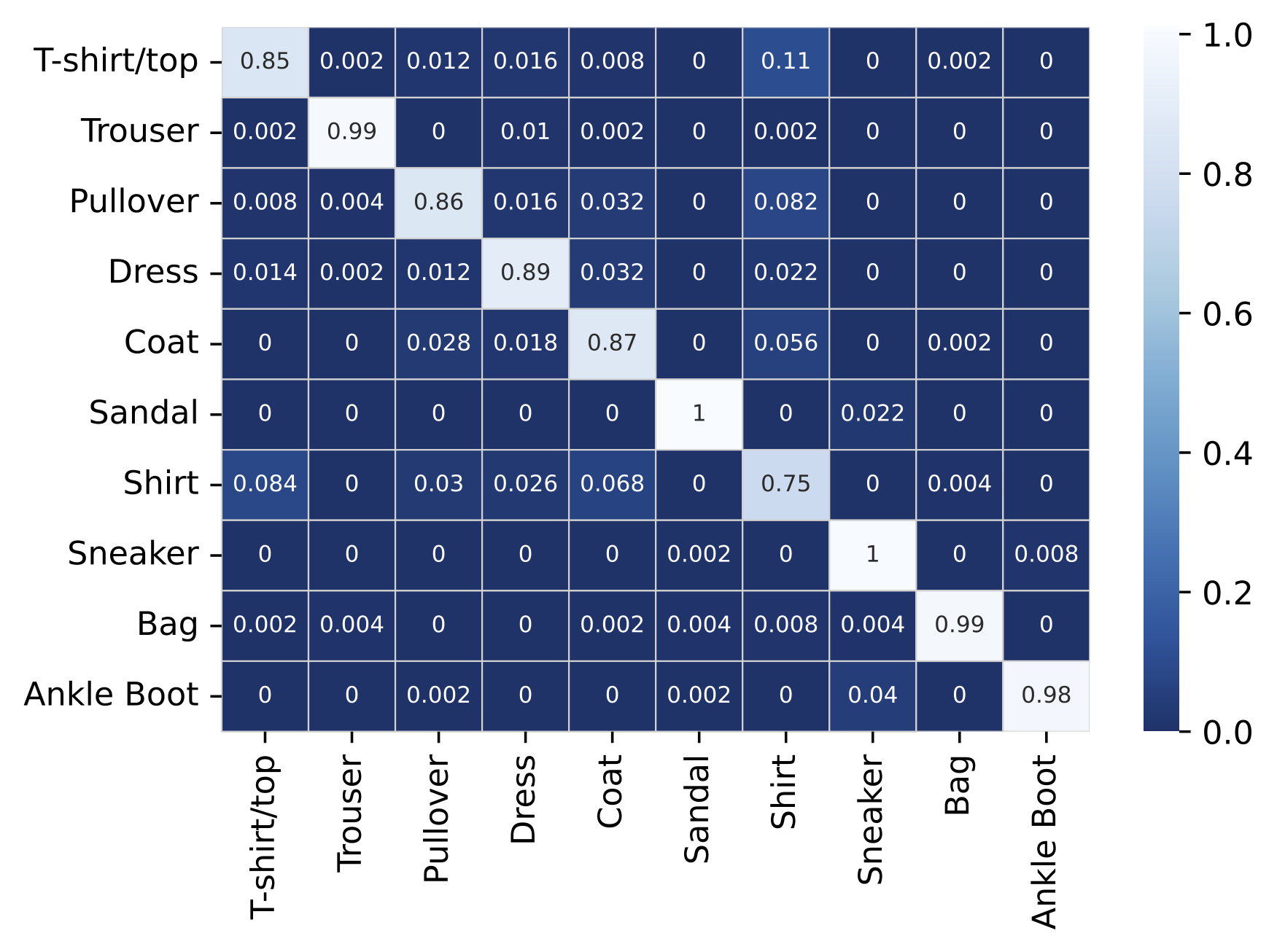
- R: Una matriz de confusión es una tabla que resume el desempeño predictivo de un modelo de clasificación. El cálculo de las métricas que contiene debe realizarse sobre el conjunto de pruebas, observaciones que no fueron utilizadas durante el proceso de entrenamiento del modelo para dar cuenta sobre la generalización del modelo en datos que nunca ha visto. Abajo hay un ejemplo de matriz de confusión sobre un modelo de imagenes que busca clasificar entre 10 tipos de vestimentas del dataset FashionMNIST. La diagonal representa el accuracy para cada una de las clases, mientras más blanco el color de la diagonal mejor, en este caso mayor número de imagenes de prendas fueron correctamente clasificadas en su categoría. En cambio, las celdas que no son parte de la diagonal representan el error que el modelo incurrió clasificando respecto a las 9 clases restantes. En particular se observa que el modelo presenta mayores dificultades en clasificar imagenes de shirt: \(75\)% de accuracy y en la mayoría de los casos las confunde con T-shirt/top y coat con un error de \(8.4\)% y \(6.8\)% respectivamente.
What does export save?
- R: El comando
learn.export()guarda un archivo con extension.pklcon el valor de los parámetros entrenados y la arquitectura del modelo para cargarlo e instanciarlo posteriormente. Un archivo.pkles un archivo pickle creado por un modulo de python que serializa objetos en una serie de bites.
- R: El comando
What is it called when we use a model for making predictions, instead of training?
- R: Cuando utilizamos un modelo para realizar predicciones se le conoce por inferencia, esta siendo utilizado como programa y no en modo de entrenamiento o ajuste. No confundir con el término estadístico.
What are IPython widgets?
- R: Los widgets de IPython es una forma de utilizar javascript en el contexto de jupyter notebook. Recordemos que cuando trabajamos con jupyter notebook tenemos un servidor local corriendo detrás, por lo que podemos tomar ventajas de tecnologías web.
When would you use a CPU for deployment? When might a GPU be better?
- R: Si el modelo no requiere capacidad para responder a un gran flujo de consultas el uso de CPU para el deployment es recomendable por su costo y administración. Evitando el gasto innecesario de usar una GPU para realizar multiples inferencias si la aplicación no copa la capacidad de esta y las mayores dificultades técnicas de gestionarlas. Por lo tanto, la ventaja de ocupar GPU es cuando el modelo recibe un gran número de solicitudes simultaneas para realizar inferencia y que la GPU puede procesar al mismo tiempo.
What are the downsides of deploying your app to a server, instead of to a client (or edge) device such as a phone or PC?
- Envio de información del dispositivo edge al servidor puede implicar mayores recursos computacionales para mantener tiempos de latencia tolerables al cliente.
- Temas de privacidad de información y compliance producto de enviar los datos al servidor.
What are three examples of problems that could occur when rolling out a bear warning system in practice?
- Detectar osos en imagenes capturadas de noche, debido a que el conjunto de datos de entrenamiento solo contiene imagenes de día, la inferencia sobre este tipo de observaciones será de mala calidad predictiva.
- Que los tiempos de inferencias esten dentro de lo necesario para que el guardaparques pueda responder de manera oportuna a la alertas. Por más que el sistema identifique correctamente a los osos, si se demora demasiado carece de utilidad en producción.
- Diferentes posiciones de osos que las camaras puedan captar y que no se encuentran representadas en el conjunto de entrenamiento. Por lo que serán ignoradas por el modelo o tendrá una mala calidad predictiva.
- Nota: recordar que los posibles comportamientos de una red neuronal emergen del intento del modelo por ajustar el ejemplo que quiere predecir al conjunto de entrenamiento sobre el cual fue entrenado y que representa una distribución particular.
What is out-of-domain data?
- R: En general, el concepto hace referencia a datos que difieren respecto a los datos utilizados para entrenar el modelo, como los descritos en los ejemplos de la respuesta anterior.
What is domain shift?
- R: Los datos que el modelo insume en producción cambian con el tiempo, distanciandose cada vez mas respecto del conjunto de datos que se utilizó para ajustar el modelo y afectando su desempeño sobre nuevas observaciones. Por ejemplo los gustos en música van adaptandose a nuevas tendencias y estilos culturales que van emergiendo en cada generación, por lo que un modelo estático que solo ha sido entrenado una vez y no toma en consideración estos cambios verá mermada su utilidad en el tiempo.
What are the three steps in the deployment process?
- Proceso manual: correr modelo en paralelo y revisar todas las predicciones para tener idea del estado del modelo, así como potenciales problemas y mejoras. Importante que las predicciones no gatillen ningúna acción automática y el proceso sea ejecutado de manera manual.
- Lanzamiento con alcance limitado: modelo en funcionamiento con alcance limitado y de bajo riesgo. Esto puede ser definido por zona geográfica o funcionamiento sobre un periodo de tiempo acotado. La constante supervision humana es importante.
- Expansion gradual: aumentar el alcance del modelo gradualmente, se requieren buenos sistema de monitoreo y reporte para detectar cualquier problema relevante, pensando que ya no tendremos el input de quien realizaba la ejecución manual respecto a nuevos comportamientos que el proceso debe tomar en cuenta. Considerar siempre que podria salir mal.